The Race to Efficiency: A New Lens on AI Scaling

AI models are growing at an unprecedented pace, with breakthroughs like ChatGPT and GPT-4 transforming how we interact with technology. But as these models expand, so do the challenges of training them efficiently. Training a single large-scale model can cost hundreds of millions of dollars and consume energy equivalent to powering a small town. This raises a critical question: how do we continue advancing AI without exhausting financial and environmental resources?
Classical AI scaling laws, such as those introduced by Kaplan (2020) and Hoffmann (2022), predict training performance based on static compute budgets. These laws have guided much of the progress in AI, but they overlook key factors like time and energy efficiency. Addressing these gaps is essential if we are to sustain AI progress as models and datasets scale exponentially.
For those interested in the technical framework tackling this challenge, explore my arXiv article.
A Paradigm Shift: Efficiency Meets Time
For decades, Moore’s Law set the pace for technological innovation, predicting that the number of transistors on a chip would double roughly every two years. This exponential growth revolutionized computing, shrinking devices and boosting performance in ways once thought impossible. But Moore’s Law wasn’t just about transistors — it embodied the power of efficiency gains over time.
Classical AI scaling laws, such as those by Kaplan (2020) and Hoffmann (2022), are similar in spirit but static in nature. They predict how training performance scales with a fixed compute budget, offering a snapshot of AI progress. However, they fail to capture the reality that efficiency — whether in hardware, algorithms, or architectures — improves continuously over time.
To address this gap, I propose a dynamic, time-aware extension to these scaling laws. At its heart is the Relative-Loss Equation, which integrates time and efficiency improvements into our understanding of AI scaling.
Introducing the Relative-Loss Equation
To understand how efficiency impacts AI training over time, let’s break down the Relative-Loss Equation:
L(t) = L₀ × R(t)
Here’s what the terms mean:
• L(t): The training loss at time t , which measures how “wrong” a model is at predicting outcomes.
• L₀: The initial training loss when we start.
• R(t): The “relative loss,” which accounts for how efficiency improvements and diminishing returns shape training over time.
The relative loss, R(t), evolves as:
R(t) = (1 + (2^(γ × t) − 1) / (γ × ln(2) × 1 year))⁻ᵏ
To simplify:
• γ: The efficiency-doubling rate, such as 𝛄= 0.5 , meaning efficiency doubles every two years.
• κ: A scaling exponent that reflects diminishing returns as more compute is added.
• t : Time, measured in years.
For example, if 𝛄 = 2 (doubling efficiency every six months), training times shrink dramatically compared to slower doubling rates. For readers interested in the mathematical details, my arXiv article provides a full derivation.
This equation captures the interplay between efficiency and diminishing returns, helping us understand why efficiency gains are essential for scaling AI in realistic timeframes.
What Does This Mean?
The Relative-Loss Equation provides two key insights:
1. Small kappa (𝜅) values mean diminishing returns.
In AI scaling, kappa (κ) — the scaling exponent — represents how quickly training loss decreases as more compute is added. For large language models, 𝜅 tends to be very small (around 0.05), meaning that simply throwing more compute at the problem yields diminishing returns. It takes exponentially more resources to achieve the same level of improvement.
2. Higher gamma (𝛄) values make breakthroughs feasible.
Gamma (γ) — the efficiency-doubling rate — is the game-changer. Faster doubling rates dramatically shorten the time needed to achieve performance milestones. For example, with 𝛄= 2.0 (efficiency doubling every six months), training that might otherwise take decades can be completed in just five years.
Key Insight: The Role of Efficiency Doubling
The Relative-Loss Equation reveals a striking insight: efficiency is the linchpin for scaling AI. Without consistent gains in efficiency, achieving meaningful improvements in AI performance would be nearly impossible.
• Training time: Without efficiency gains, reducing training loss to meaningful levels would take thousands of years — even with current state-of-the-art hardware.
• Hardware demand: Alternatively, organizations would need GPU fleets so large that their energy requirements would rival those of entire continents.
By increasing the efficiency-doubling rate (gamma), these extreme scenarios can be avoided:
• Doubling efficiency every two years (gamma = 0.5) shrinks timelines to decades.
• Doubling every six months (gamma = 2.0) reduces the same milestones to just a few years.
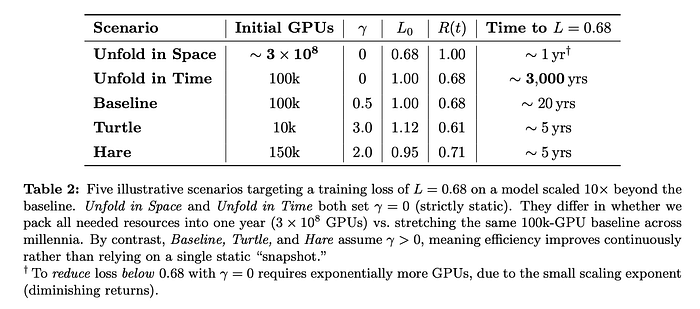
Real-World Implications
The Relative-Loss Equation doesn’t just offer theoretical insights — it provides practical guidance for organizations, policymakers, and researchers grappling with the realities of scaling AI systems. Here’s how these insights apply to real-world scenarios:
1. Balancing GPU Investments and Innovation
Organizations face a critical decision:
• Should they front-load investments into massive GPU fleets to meet immediate performance targets?
• Or should they focus on incremental efficiency improvements to achieve sustainable progress over time?
This trade-off isn’t just about cost — it’s about long-term strategy. Front-loading hardware may seem attractive for short-term gains, but it risks becoming obsolete as efficiency improvements accelerate. On the other hand, a deliberate focus on R&D to improve efficiency can reduce costs and training timelines while ensuring scalability for future advancements.
Example:
Consider two approaches to training a large model:
• Front-Loading (the “Hare”): An organization deploys a massive GPU fleet to achieve its target quickly but at high upfront costs.
• Incremental Innovation (the “Turtle”): Another organization starts with fewer GPUs but invests in R&D to double efficiency every six months, eventually outpacing the first in cost-effectiveness and scalability.
The right balance depends on an organization’s priorities, resources, and long-term vision. My framework quantifies these trade-offs, enabling leaders to make informed decisions.
2. A Roadmap for Efficiency Doubling
Policymakers and industry leaders can use the concept of efficiency doubling to guide innovation. Just as Moore’s Law once provided clear targets for semiconductor advancements, the efficiency-doubling rate (gamma) can serve as a north star for AI scaling. Setting ambitious yet achievable goals — such as doubling efficiency every 12 months — can align efforts across hardware, software, and infrastructure development.
3. Example Goals for Efficiency Doubling:
• Hardware: Encourage the development of AI accelerators that support lower-precision arithmetic (e.g., FP8) without sacrificing accuracy.
• Software: Invest in distributed training algorithms and techniques, low-precision arithmetics, and sparsity that minimize wasted compute.
• Infrastructure: Optimize data pipelines and networking to reduce bottlenecks and improve resource utilization.
By prioritizing efficiency improvements, organizations can achieve exponential progress without running into financial or energy constraints.
Conclusion: A Race to Efficiency
This work reveals that AI scaling is not just a matter of throwing more compute at the problem — it’s a race to improve how efficiently compute is used. By embedding time and efficiency into the core of scaling laws, we gain a roadmap for sustainable AI progress.
The next decade of AI progress will depend not just on building larger models but on building them efficiently that can sustain exponential growth in a world of finite resources.
What are your thoughts on this race to efficiency? Let’s discuss in the comments!
References
1. Kaplan et al. (2020)
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling laws for neural language models. arXiv:2001.08361.
2. Hoffmann et al. (2022)
Hoffmann, J., Borgeaud, S., Mensch, A., Cai, T., Rutherford, E., de Las Casas, D., Hendricks, L. M., Welbl, J., Clark, A., Bewersdorf, J., et al. (2022). Training compute-optimal large language models. arXiv:2203.15556.
